What is ML ?
ML is a way to get predictive insights from data to make repeated decisions off of. You can train the software to estimate the amount of taxes that you owe. Or train that same software to estimate the amount of time it will take to get you home. The ML software once trained on your specific use case is called a Model.
Whatever the domain ML modeling requires lots of training examples. We’ll train the model to estimate tax by showing it many, many, many examples of prior year tax returns. An example consists of an input and the correct answer for that input, that’s called the Label.
So why do we say these algorithms are standard? Well, the algorithms exist independently of your use case. Even though detecting manufacturing defects and parts in those images and detecting something like diseased leaves and tree images, are two very different use cases, the same algorithm an image classification network works for both. Similarly, there are standard algorithms for predicting the future value of a time series dataset or to transcribe human speech to text. When you use the same algorithm on different datasets, there are different features or inputs relative to the different use cases. So even though we start with the same standard algorithm, after training the trained model that classifies leaves is different from the trained model that classifies manufacturing parts.
The main thing to know is that for Machine Learning your model will only be as good as your data.
AI refers to machines that are capable of acting autonomously, machines that think. AI has to do with the theory and methods to build machines that can solve problems by thinking and acting like humans.Start transcript at Machine Learning within there is a tool set like Newton’s Laws of Mechanics. Deep Learning is a type of Machine Learning that works even when the data consists of unstructured data, like images, speech, video, natural language text and so on. The basic difference between Machine Learning and other techniques in AI is that in Machine Learning machines learn. They don’t start out intelligent, they become intelligent.
Much of the hype around ML now is because the barriers to entry a building these models has fallen dramatically. This is because the convergence of a number of critical factors, the increasing availability of data.The increasing maturity and sophistication of those ML algorithms for you to choose from. And the increasing power in the availability of computing hardware and software through things like cloud computing.
in GCP :


PRebuilt ML model APIS
When we say unstructured data, we are referring to the data that comes in the form of audio, video, images, freeform text, etc.
Let’s give a few real-world example of businesses using unstructured data in their products. Can you differentiate between snow and cloud cover in these two images? One of GCP’s customer, Airbus Defense and Space, works with satellite imagery such as this, and it’s very important that they can detect and correct imperfections in the images, such as the presence of cloud formations. Historically, this imperfection correcting process was time-consuming, prone to error, and not scalable. Airubs solved these issues with machine learning.


The NLP API provides many features with which text analytics can be performed. The first feature is Syntactic Analysis. Syntactic Analysis first breaks up text into a series of tokens, which are generally words and sentences, and provides information about the tokens internal structure and its role in the sentence. It can label a token as a noun or a verb, singular or plural, first person or second person, masculine, feminine or neutral. And provides grammatical information such as case, tense, mood and voice.
Lab :Using the Natural Language API to classify unstructured text
Task 1: Confirm that the Cloud Natural Language API is enabled
Task 2: Create an API Key
Task 3: Classify a news article
We create json file in the editor with the following content
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}send this text to the Natural Language API’s classifyText method with the following curl command:
curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonOutput :
{ categories:
[
{
name: '/Food & Drink/Cooking & Recipes',
confidence: 0.85
},
{
name: '/Food & Drink/Food/Meat & Seafood',
confidence: 0.63
}
]
}Task 4: Classifying a large text dataset
Task 5: Creating a BigQuery table for our categorized text data
Create a dataset and a new table with 3 columns that will be filled by our code
Task 6: Classifying news data and storing the result in BigQuery
Create a service account :
gcloud iam service-accounts create my-account --display-name my-account gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com export GOOGLE_APPLICATION_CREDENTIALS=key.json
The python code :
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project id below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_classification_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('text-classification-codelab').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((str(article_text), str(nl_response.categories[0].name), str(nl_response.categories[0].confidence)))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.insert_rows(table, rows_for_bq)
assert errors == []Run the script :
python3 classify-text.py
Task 7: Analyzing categorized news data in BigQuery
We go to big query and query the data in the table we created
Cloud AI Platform notebooks
Standard software development tools are not very efficient for writing code for data analysis and machine learning. Data analysis and machine learning coding often involve looking at plots, repeatedly executing small chunks of code with minor changes, and frequently having to print output. Iteratively, running whole scripts for this task is burdensome. These were some of the issues that motivated the development of notebooks. Notebook environments seamlessly integrate commentary, plots, and code.

Collaborative notebook, with installed libraries and collaborative step by step alogirthm creations and annotation

magic functions allow you to execute system commands from within notebook cells.This is useful for checking query correctness and output. The BigQuery magic function allows you to save the query output to a Pandas data frame so that you can manipulate it further.
Lab BigQuery in Jupyter Labs on AI Platform
Start a JupyterLab Notebook Instance
Notebooks for AI Platform -> NEW INSTANCE -> Python -> OPEN JUPYTERLAB -> Python 3 ->
First cell :
%%bigquery df SELECT departure_delay, COUNT(1) AS num_flights, APPROX_QUANTILES(arrival_delay, 10) AS arrival_delay_deciles FROM `bigquery-samples.airline_ontime_data.flights` GROUP BY departure_delay HAVING num_flights > 100 ORDER BY departure_delay ASC
View dataframe :
df.head()
Additional setup of the data and final plot :
Enter the following code in a new cell to convert the list of arrival_delay_deciles into a Pandas Series object. Since we want to relate departure delay times to arrival delay times we have to concatenate our percentiles table to the departure_delay field in our original DataFrame. fore plotting the contents of our DataFrame, we’ll want to drop extreme values stored in the 0% and 100% fields.
import pandas as pd
percentiles = df['arrival_delay_deciles'].apply(pd.Series)
percentiles.rename(columns = lambda x : '{0}%'.format(x*10), inplace=True)
percentiles.head()
df = pd.concat([df['departure_delay'], percentiles], axis=1)
df.head()
df.drop(labels=['0%', '100%'], axis=1, inplace=True)
df.plot(x='departure_delay', xlim=(-30,50), ylim=(-50,50));
Documentation on pandas : https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
Productionizing custom ML models

You may want a more tailored model trained on your own data. For that, we will need a custom model.There are a few ways of doing custom model development, training, and serving. We will highlight a few major ways and then focus on four :






Kubeflow

The capabilities provided by Kubeflow Pipelines can largely be put into three buckets: ML workflow orchestration, share, reuse, and composed, rapid reliable experimentation.

AI Hub
AI Hub is a repository for ML components. Don’t reinvent the wheel. Avoid buildings some component when someone else has already built it, and most likely has already optimized it.Among the assets stored on AI Hub are entire Kubeflow Pipelines, Jupyter notebooks, TensorFlow modules, fully trained models, services and VM images.
Lab : Running AI models on Kubeflow
Kubernetes is a mature, production ready platform that gives developers a simple API to deploy programs to a cluster of machines as if they were a single piece of hardware. Using Kubernetes, computational resources can be added or removed as desired, and the same cluster can be used to both train and serve ML models.This lab will serve as an introduction to Kubeflow, an open-source project which aims to make running ML workloads on Kubernetes simple, portable and scalable.
What You’ll Learn
- How to set up a Kubeflow cluster on GCP
- How to package a TensorFlow program in a container, and upload it to Google Container Registry
- How to submit a Tensorflow training job, and save the resulting model to Google Cloud Storage
- How to serve and interact with a trained model
My god.. Easily the most difficult and long Lab
You successfully set up Kubeflow on a Kubernetes Engine cluster, used Kubeflow to deploy a TensorFlow model training service, and deployed an interactive API based on the trained model.

BigQuery ML
BigQuery Machine Learning allows you to build machine learning models using SQL syntax.
First, we must write a query on data stored in BigQuery to extract our training data. Then, we can create a model where we specify a model type and other hyperparameters. After the model is trained, we can evaluate the model and verify that it meets our requirements. Finally, we can make predictions using our model on data extracted from BigQuery.



First, we have another example of linear classification or what is also called logistic regression. In this example, we’re using a flights arrivals data set to predict whether a flight would be on time or not, which is a binary outcome. For logistic regression, we simply need to specify the type of model and the label we’re trying to predict. For more advanced users, there are other options such as if you want your model to use regularization. While logistic regression models are the Swiss army knife of machine learning, deep neural networks or DNN’s allow you to better model nonlinear relationships in your data. An example of a non-linear relationship would be in a car depreciation. A car loses a vast majority of its value within the first few years after which the value more or less stabilizes.
Here are the modal options available in BigQuery ML to forecast things like numeric values. So far, we’ve only talked about classification. You can also use BQML to do regression. In this example, we’re fitting a linear regression model to predict taxi fare based on features such as the hour of day, pick-up and drop off location, and the day of the week. If you need a model more complex than linear regression, you can use a DNN regressor in BQML.
Let’s wrap up with unsupervised machine learning. Supervised is when you have labeled training data, meaning you know the answer in the past and unsupervised is where you are using no such label.
Lab : Predict Bike Trip Duration with a Regression Model in BQML
Objectives
In this lab, you learn to perform the following tasks:
- Query and explore the London bicycles dataset for feature engineering
- Create a linear regression model in BQML
- Evaluate the performance of your machine learning model
- Extract your model weight
Basic model :
CREATE OR REPLACE MODEL
bike_model.model
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
CAST(EXTRACT(dayofweek
FROM
start_date) AS STRING) AS dayofweek,
CAST(EXTRACT(hour
FROM
start_date) AS STRING) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hireTo see the metrics of the model :
SELECT * FROM ML.EVALUATE(MODEL `bike_model.model`)
Final model with some transformation and data aggregation :
CREATE OR REPLACE MODEL
bike_model.model_bucketized
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(hour
FROM
start_date),
[5, 10, 17]) AS hourofday
FROM
`bigquery-public-data`.london_bicycles.cycle_hireOur best model contains several data transformations. Wouldn’t it be nice if BigQuery could remember the sets of transformations we did at the time of training and automatically apply them at the time of prediction? It can, using the TRANSFORM clause!
In this case, the resulting model requires just the start_station_name and start_date to predict the duration. The transformations are saved and carried out on the provided raw data to create input features for the model. The main advantage of placing all preprocessing functions inside the TRANSFORM clause is that clients of the model do not have to know what kind of preprocessing has been carried out.
CREATE OR REPLACE MODEL
bike_model.model_bucketized TRANSFORM(* EXCEPT(start_date),
IF
(EXTRACT(dayofweek
FROM
start_date) BETWEEN 2 AND 6,
'weekday',
'weekend') AS dayofweek,
ML.BUCKETIZE(EXTRACT(HOUR
FROM
start_date),
[5, 10, 17]) AS hourofday )
OPTIONS
(input_label_cols=['duration'],
model_type='linear_reg') AS
SELECT
duration,
start_station_name,
start_date
FROM
`bigquery-public-data`.london_bicycles.cycle_hireWith the TRANSFORM clause in place, enter this query to predict the duration of a rental from Park Lane right now
SELECT
*
FROM
ML.PREDICT(MODEL bike_model.model_bucketized,
(
SELECT
'Park Lane , Hyde Park' AS start_station_name,
CURRENT_TIMESTAMP() AS start_date) )To check model weights :
SELECT * FROM ML.WEIGHTS(MODEL bike_model.model_bucketized)
Lab : Movie Recommendations in BigQuery ML
Objectives
In this lab, you learn to perform the following tasks:
- Train a recommendation model in BigQuery
- Make product predictions for both single users and batch users
Task 1: Get MovieLens Data
Make a bucket and download data
bq --location=EU mk --dataset movies curl -O 'http://files.grouplens.org/datasets/movielens/ml-20m.zip' unzip ml-20m.zip bq --location=EU load --source_format=CSV \ --autodetect movies.movielens_ratings ml-20m/ratings.csv bq --location=EU load --source_format=CSV \ --autodetect movies.movielens_movies_raw ml-20m/movies.csv
Task 2: Explore the Data
SELECT COUNT(DISTINCT userId) numUsers, COUNT(DISTINCT movieId) numMovies, COUNT(*) totalRatings FROM movies.movielens_ratings SELECT * FROM movies.movielens_movies_raw WHERE movieId < 5
We can see that the genres column is a formatted string. Parse the genres into an array and rewrite the results into a table named movielens_movies.
CREATE OR REPLACE TABLE movies.movielens_movies AS SELECT * REPLACE(SPLIT(genres, "|") AS genres) FROM movies.movielens_movies_raw
Task 3: Collaborative Filtering
Creation of the model and evaluation
CREATE OR REPLACE MODEL
movies.movie_recommender
OPTIONS
(model_type='matrix_factorization',
user_col='userId',
item_col='movieId',
rating_col='rating',
l2_reg=0.2,
num_factors=16) AS
SELECT
userId,
movieId,
rating
FROM
movies.movielens_ratings
SELECT * FROM ML.EVALUATE(MODEL `cloud-training-prod-bucket.movies.movie_recommender`)Task 4: Making Recommendations
Let’s find the best comedy movies to recommend to the user whose userId is 903. Enter the query below:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-prod-bucket.movies.movie_recommender`,
(
SELECT
movieId,
title,
903 AS userId
FROM
`movies.movielens_movies`,
UNNEST(genres) g
WHERE
g = 'Comedy' ))
ORDER BY
predicted_rating DESC
LIMIT
5 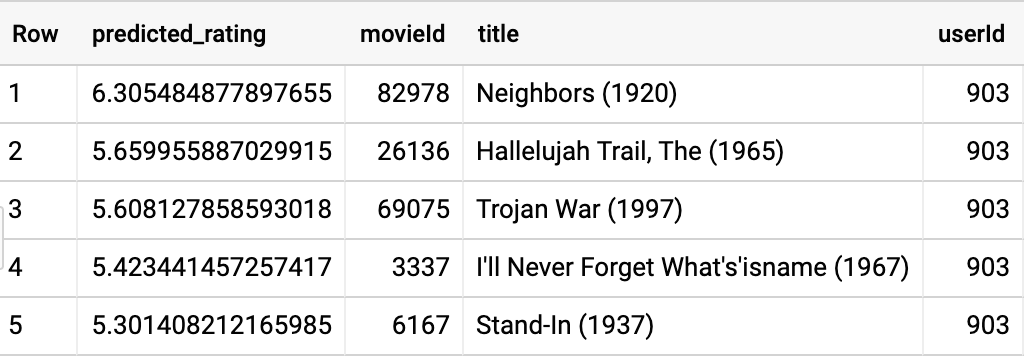
This result includes movies the user has already seen and rated in the past. Let’s remove them:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-prod-bucket.movies.movie_recommender`,
(
WITH
seen AS (
SELECT
ARRAY_AGG(movieId) AS movies
FROM
movies.movielens_ratings
WHERE
userId = 903 )
SELECT
movieId,
title,
903 AS userId
FROM
movies.movielens_movies,
UNNEST(genres) g,
seen
WHERE
g = 'Comedy'
AND movieId NOT IN UNNEST(seen.movies) ))
ORDER BY
predicted_rating DESC
LIMIT
5Task 5: Customer Targeting
We wish to get more reviews for movieId=96481 which has only one rating and we wish to send coupons to the 100 users who are likely to rate it the highest. Identify those users using:
SELECT
*
FROM
ML.PREDICT(MODEL `cloud-training-prod-bucket.movies.movie_recommender`,
(
WITH
allUsers AS (
SELECT
DISTINCT userId
FROM
movies.movielens_ratings )
SELECT
96481 AS movieId,
(
SELECT
title
FROM
movies.movielens_movies
WHERE
movieId=96481) title,
userId
FROM
allUsers ))
ORDER BY
predicted_rating DESC
LIMIT
100The result gives us 100 users to target
Task 6: Batch predictions for all users and movies
Enter the following query to obtain batch predictions:
SELECT * FROM ML.RECOMMEND(MODEL `cloud-training-prod-bucket.movies.movie_recommender`) LIMIT 100000
Cloud Auto ML
Cloud AutoML is a service on Google Cloud platform that allows you to build powerful machine learning models with minimal effort and machine learning expertise.

Cloud AutoML uses a prepared data set to train a custom model. You can make small prepared datasets for experimentation directly in the web UI but it is more common to assemble the information in a CSV comma separated value file. The CSV file must be utf-8 encoded and located in the same cloud storage bucket as the source files. You can also create and manage prepared datasets programmatically in Python, Java, or Node.js.
With Cloud AutoML you can create smaller more specialized custom models and use them programmatically.
Now we’ll describe AutoML Vision. This is a Cloud AutoML product for image data. Cloud AutoML Vision specializes in training models for image classification.
Cloud auto ML natural language specializes in training models for text data. For example, if you have a set of newspaper articles, you can use the auto ML NLP service to classify if a given article is for example about sports or politics.
While AutoML vision and NLP are for unstructured data, AutoML table is for structured data. The development of AutoML table is a collaboration with the Google brain team, while the technical details of the project haven’t been released yet to the public. The team basically took the architecture search capability used for image classification and translation problems, and found a way to apply it to tabular data.


